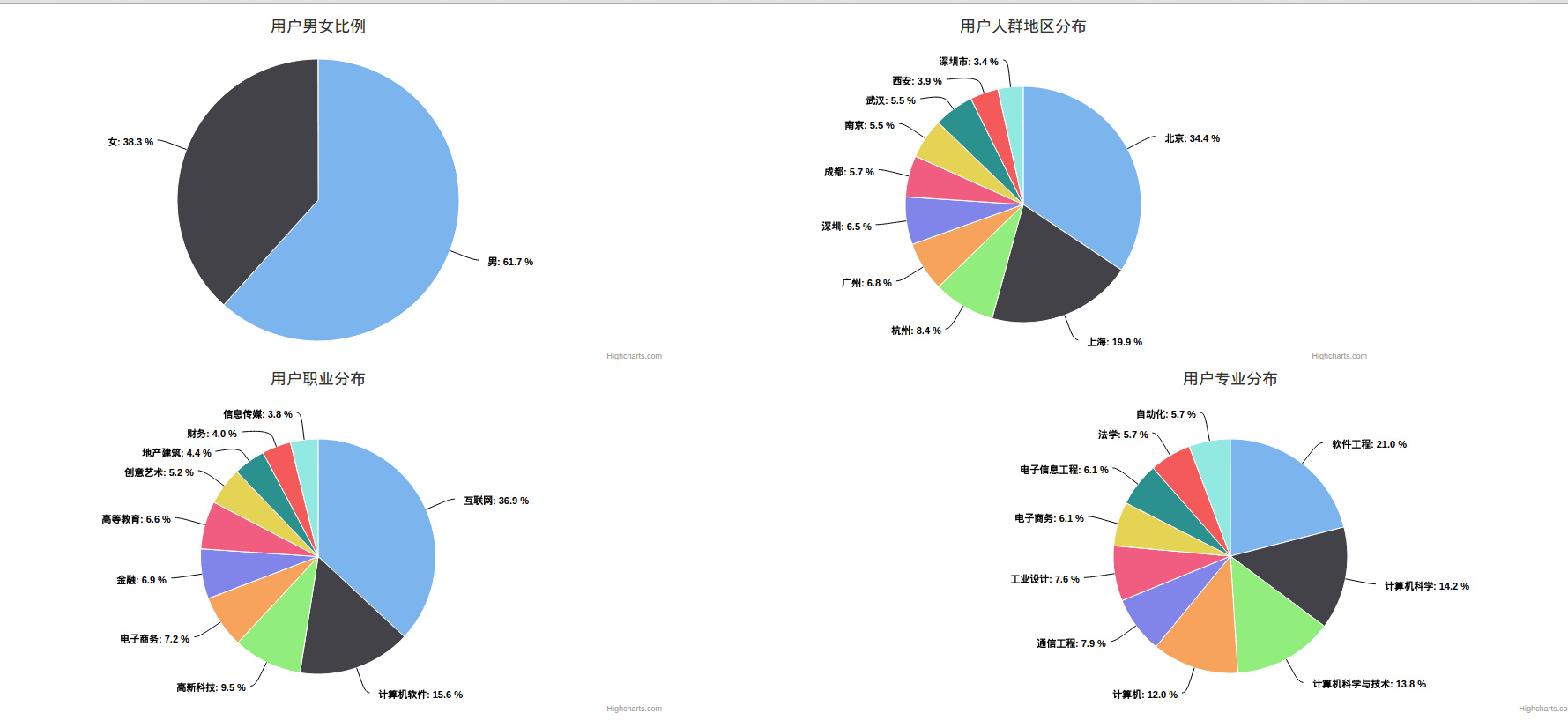
开发前的准备

一个个地复制,以”__utma=?;__utmb=?;”这样的形式组成一个cookie字符串。接下来就可以使用该cookie字符串来发送请求。
初始的示例:
$url = "http://www.zhihu.com/people/mora-hu/about"; //此处mora-hu代表用户ID$ch = curl_init($url); //初始化会话curl_setopt($ch, CURLOPT_HEADER, 0);curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr["user_cookie"]); //设置请求COOKIEcurl_setopt($ch, CURLOPT_USERAGENT, $_SERVER["HTTP_USER_AGENT"]);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch);return $result; //抓取的结果运行上面的代码可以获得mora-hu用户的个人中心页面。利用该结果再使用正则表达式对页面进行处理,就能获取到姓名,性别等所需要抓取的信息。
function getImg($url, $u_id){if (file_exists("./images/" . $u_id . ".jpg")){return "images/$u_id" . ".jpg";}if (empty($url)){return "";}$context_options = array( "http" => array("header" => "Referer:http://www.zhihu.com"//带上referer参数 ) );$context = stream_context_create($context_options); $img = file_get_contents("http:" . $url, FALSE, $context);file_put_contents("./images/" . $u_id . ".jpg", $img);return "images/$u_id" . ".jpg";}2、爬取更多用户
这里有两个链接,一个是关注了,另一个是关注者,以“关注了”的链接为例。用正则匹配去匹配到相应的链接,得到url之后用curl带上cookie再发一次请求。抓取到用户关注了的用于列表页之后,可以得到下面的页面:
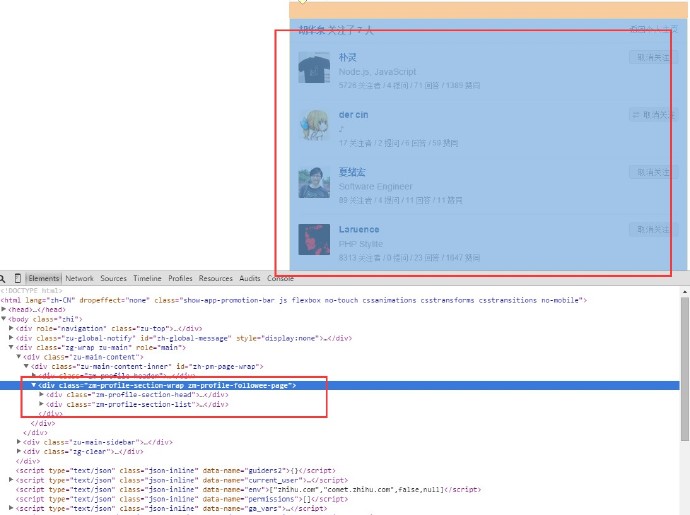
分析页面的html结构,因为只要得到用户的信息,所以只需要框住的这一块的div内容,用户名都在这里面。可以看到,用户关注了的页面的url是:

不同的用户的这个url几乎是一样的,不同的地方就在于用户名那里。用正则匹配拿到用户名列表,一个一个地拼url,然后再逐个发请求(当然,一个一个是比较慢的,下面有解决方案,这个稍后会说到)。进入到新用户的页面之后,再重复上面的步骤,就这样不断循环,直到达到你所要的数据量。
3、Linux统计文件数量
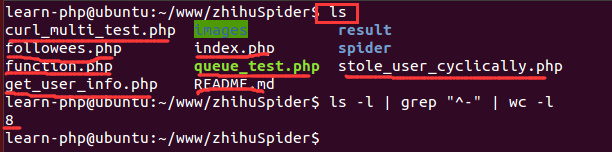
脚本跑了一段时间后,需要看看究竟获取了多少图片,当数据量比较大的时候,打开文件夹查看图片数量就有点慢。脚本是在Linux环境下运行的,因此可以使用Linux的命令来统计文件数量:
ls -l | grep "^-" | wc -l其中, ls -l 是长列表输出该目录下的文件信息(这里的文件可以是目录、链接、设备文件等); grep "^-" 过滤长列表输出信息, "^-" 只保留一般文件,如果只保留目录是 "^d" ; wc -l 是统计输出信息的行数。下面是一个运行示例:
4、插入MySQL时重复数据的处理
程序运行了一段时间后,发现有很多用户的数据是重复的,因此需要在插入重复用户数据的时候做处理。处理方案如下:
1)插入数据库之前检查数据是否已经存在数据库;
2)添加唯一索引,插入时使用 INSERT INTO ... ON DUPLICATE KEY UPDATE...
3)添加唯一索引,插入时使用 INSERT INGNORE INTO...
4)添加唯一索引,插入时使用 REPLACE INTO...
第一种方案是最简单但也是效率最差的方案,因此不采取。二和四方案的执行结果是一样的,不同的是,在遇到相同的数据时, INSERT INTO … ON DUPLICATE KEY UPDATE 是直接更新的,而 REPLACE INTO 是先删除旧的数据然后插入新的,在这个过程中,还需要重新维护索引,所以速度慢。所以在二和四两者间选择了第二种方案。而第三种方案, INSERT INGNORE 会忽略执行INSERT语句出现的错误,不会忽略语法问题,但是忽略主键存在的情况。这样一来,使用 INSERT INGNORE 就更好了。最终,考虑到要在数据库中记录重复数据的条数,因此在程序中采用了第二种方案。
5、使用curl_multi实现多线程抓取页面
刚开始单进程而且单个curl去抓取数据,速度很慢,挂机爬了一个晚上只能抓到2W的数据,于是便想到能不能在进入新的用户页面发curl请求的时候一次性请求多个用户,后来发现了curl_multi这个好东西。curl_multi这类函数可以实现同时请求多个url,而不是一个个请求,这类似于linux系统中一个进程开多条线程执行的功能。下面是使用curl_multi实现多线程爬虫的示例:
$mh = curl_multi_init(); //返回一个新cURL批处理句柄for ($i = 0; $i < $max_size; $i++){$ch = curl_init(); //初始化单个cURL会话curl_setopt($ch, CURLOPT_HEADER, 0);curl_setopt($ch, CURLOPT_URL, "http://www.zhihu.com/people/" . $user_list[$i] . "/about");curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36");curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);$requestMap[$i] = $ch;curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄}$user_arr = array();do {//运行当前 cURL 句柄的子连接while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);if ($cme != CURLM_OK) {break;}//获取当前解析的cURL的相关传输信息while ($done = curl_multi_info_read($mh)){$info = curl_getinfo($done["handle"]);$tmp_result = curl_multi_getcontent($done["handle"]);$error = curl_error($done["handle"]);$user_arr[] = array_values(getUserInfo($tmp_result));//保证同时有$max_size个请求在处理if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list)){$ch = curl_init();curl_setopt($ch, CURLOPT_HEADER, 0);curl_setopt($ch, CURLOPT_URL, "http://www.zhihu.com/people/" . $user_list[$i] . "/about");curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36");curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);$requestMap[$i] = $ch;curl_multi_add_handle($mh, $ch);$i++;}curl_multi_remove_handle($mh, $done["handle"]);}if ($active)curl_multi_select($mh, 10);} while ($active);curl_multi_close($mh);return $user_arr;6、HTTP 429 Too Many Requests<?php$redis = new Redis();$redis->connect("127.0.0.1", "6379");$redis->set("tmp", "value");if ($redis->exists("tmp")){echo $redis->get("tmp") . "
";}8、使用PHP的pcntl扩展实现多进程//PHP多进程demo//fork10个进程for ($i = 0; $i < 10; $i++) {$pid = pcntl_fork();if ($pid == -1) {echo "Could not fork!
";exit(1);}if (!$pid) {echo "child process $i running
";//子进程执行完毕之后就退出,以免继续fork出新的子进程exit($i);}}//等待子进程执行完毕,避免出现僵尸进程while (pcntl_waitpid(0, $status) != -1) {$status = pcntl_wexitstatus($status);echo "Child $status completed
";}9、在Linux下查看系统的cpu信息cat /proc/cpuinfo结果如下:
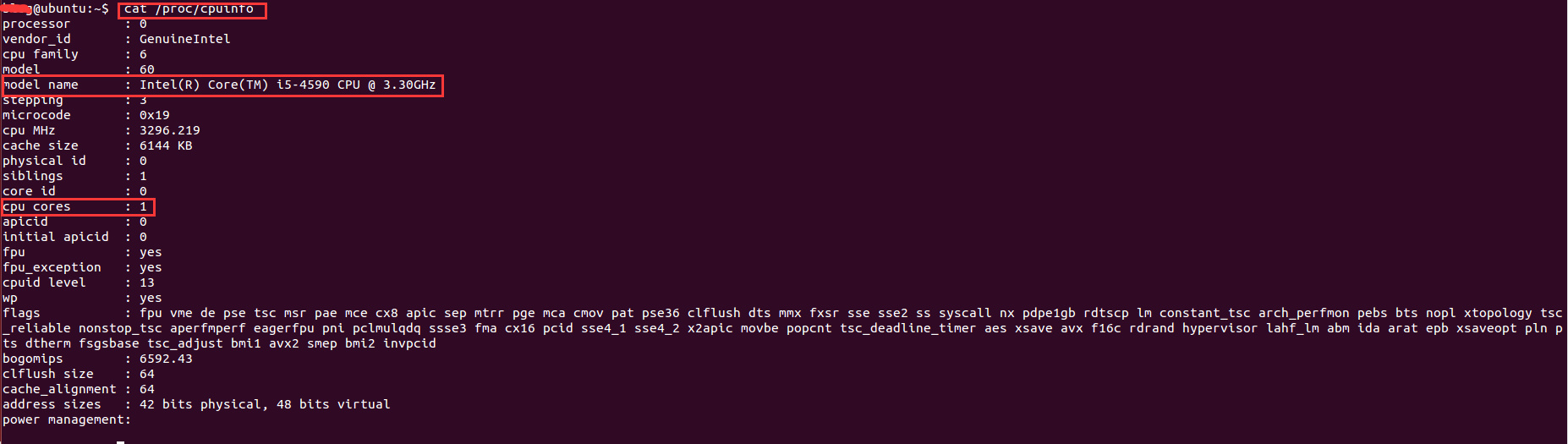
其中,model name表示cpu类型信息,cpu cores表示cpu核数。这里的核数是1,因为是在虚拟机下运行,分配到的cpu核数比较少,因此只能开2条进程。最终的结果是,用了一个周末就抓取了110万的用户数据。
10、多进程编程中Redis和MySQL连接问题
在多进程条件下,程序运行了一段时间后,发现数据不能插入到数据库,会报mysql too many connections的错误,redis也是如此。
下面这段代码会执行失败:
<?php for ($i = 0; $i < 10; $i++) { $pid = pcntl_fork(); if ($pid == -1) {echo "Could not fork!
";exit(1); } if (!$pid) {$redis = PRedis::getInstance();// do something exit; } }根本原因是在各个子进程创建时,就已经继承了父进程一份完全一样的拷贝。对象可以拷贝,但是已创建的连接不能被拷贝成多个,由此产生的结果,就是各个进程都使用同一个redis连接,各干各的事,最终产生莫名其妙的冲突。<?php public static function getInstance() { static $instances = array(); $key = getmypid();//获取当前进程ID if ($empty($instances[$key])) {$inctances[$key] = new self(); } return $instances[$key]; }11、PHP统计脚本执行时间function microtime_float(){ list($u_sec, $sec) = explode(" ", microtime()); return (floatval($u_sec) + floatval($sec));}$start_time = microtime_float();//do somethingusleep(100);$end_time = microtime_float();$total_time = $end_time - $start_time;$time_cost = sprintf("%.10f", $total_time);echo "program cost total " . $time_cost . "s
";以上就是本文的全部内容,供大家参考,希望对大家的学习有所帮助。